
Do conhecimento corporativo ao código: evoluindo aplicações com Work IQ, Foundry IQ e GitHub Copilot — Parte 1

Quem trabalha com desenvolvimento dentro de uma empresa de médio ou grande porte conhece bem aquele cenário: uma demanda chega por e-mail, outra aparece num canal do Microsoft Teams, a documentação interna está espalhada entre Wiki, Blob Storage e SharePoint, e ainda existe a documentação oficial do produto que precisa ser respeitada. Quando esse conhecimento todo não está acessível ao agente de IA, o resultado é código que ignora regras de negócio, padrões internos e diretrizes de observabilidade. A proposta deste artigo é resolver exatamente isso usando dois serviços da Microsoft que se complementam, o WorkIQ para acessar dados do ambiente Microsoft 365 e o Foundry IQ para acessar a base de conhecimento corporativa estruturada no Azure AI Search, ambos consumidos via Model Context Protocol dentro do VS Code com o GitHub Copilot. Esta é a primeira parte, onde vamos configurar a infraestrutura no Azure, entender os serviços envolvidos e descobrir os requisitos usando o WorkIQ. Na segunda parte, vamos implementar o servidor MCP e deixar o GitHub Copilot colocar tudo em prática.
O Foundry IQ é a camada de conhecimento dos agentes do Microsoft Foundry. Ele organiza fontes de dados (knowledge sources) em bases de conhecimento (knowledge bases) que ficam disponíveis para serem consultadas em linguagem natural via o Azure AI Search. Cada knowledge source pode ser um Blob Storage, um Web Crawl com domínios permitidos, um SharePoint, entre outras opções, e cada knowledge base agrupa essas fontes para responder perguntas com retrieval augmented generation usando um modelo deployado no Microsoft Foundry. Eu já cobri esse serviço em detalhes em uma série de quatro partes que recomendo a leitura, começando pela parte 1, seguindo pela parte 2, parte 3 e parte 4.
O WorkIQ, por outro lado, vive do lado do Microsoft 365 Copilot. Ele expõe via MCP os dados que o usuário já tem acesso dentro do tenant, e-mails do Outlook, mensagens de canais do Teams, arquivos do OneDrive e SharePoint, eventos de calendário e mais. Em vez de pedir para alguém te encaminhar aquele e-mail com o requisito da feature, você simplesmente pergunta ao agente, e o agente vai buscar a informação direto na sua caixa de entrada respeitando as permissões do seu usuário. É a forma de transformar a comunicação informal da empresa em contexto utilizável pelo Copilot.
O cenário que vamos endereçar é o seguinte: existe uma Order.Api já implementada e disponível no repositório deste artigo, construída em .NET 10 com Minimal APIs e Entity Framework Core In-Memory, com endpoints para criar pedidos, listar pedidos e listar produtos. O ponto de entrada é simples e delega tudo para uma extensão de configuração:
using Order.Api.Extensions;
var builder = WebApplication.CreateBuilder(args);
builder.Services.ConfigureServices();
var app = builder.Build();
app.UseServices();
app.Run();A configuração de serviços registra o OpenAPI, o AppDbContext em memória, faz o seed inicial de produtos e mapeia os endpoints:
public static IServiceCollection ConfigureServices(this IServiceCollection services)
{
services.AddOpenApi();
services.AddDbContext<AppDbContext>(options =>
options.UseInMemoryDatabase("OrderDb"));
return services;
}
public static WebApplication UseServices(this WebApplication app)
{
if (app.Environment.IsDevelopment())
{
app.MapOpenApi();
}
using (var scope = app.Services.CreateScope())
{
var db = scope.ServiceProvider.GetRequiredService<AppDbContext>();
db.Database.EnsureCreated();
SeedProducts(db);
}
app.MapApiEndpoints();
return app;
}ConfigureServices()
- Registra o OpenAPI e o
AppDbContextconfigurado com o provider In-Memory para um banco chamadoOrderDb.
UseServices()
- Habilita o endpoint do OpenAPI em ambiente de desenvolvimento, garante que o banco esteja criado, executa o seed de produtos e mapeia os endpoints da API.
O endpoint de criação de pedido recebe um DTO com a lista de itens, valida a existência de cada produto, persiste o pedido e devolve um OrderDto populado com nome e preço de cada produto:
app.MapPost("/orders", async (CreateOrderDto request, AppDbContext db) =>
{
var productIds = request.Items
.Select(i => i.ProductId)
.ToList();
var products = await db.Products
.Where(p => productIds.Contains(p.Id))
.ToDictionaryAsync(p => p.Id);
var missingIds = productIds
.Except(products.Keys)
.ToList();
if (missingIds.Count > 0)
{
return Results.BadRequest($"Products not found: {string.Join(", ", missingIds)}");
}
var order = new Entities.Order
{
Items = request.Items.Select(i => new OrderItem
{
ProductId = i.ProductId,
Quantity = i.Quantity
}).ToList()
};
db.Orders.Add(order);
await db.SaveChangesAsync();
var orderDto = new OrderDto(
order.Id,
order.CreatedAt,
order.Items.Select(i => new OrderItemDto(
i.ProductId,
products[i.ProductId].Name,
i.Quantity,
products[i.ProductId].Price
)).ToList()
);
return Results.Created($"/orders/{order.Id}", orderDto);
});Para executar a API, navegue até a pasta Order.Api e rode dotnet run. A API ficará disponível em http://localhost:5225. Para validar o comportamento base, use o arquivo Order.Api.http e execute a requisição POST create order - 2 Laptops (total ~$2599.98), que cria um pedido com dois laptops. A resposta traz o pedido criado com os itens, preço unitário e quantidade.
{
"id": 1,
"createdAt": "2026-04-23T02:13:04.021034Z",
"items": [
{
"productId": 1,
"productName": "Laptop",
"quantity": 2,
"unitPrice": 1299.99
}
]
}A API funciona, mas faltam dois pedaços importantes que chegaram fora do fluxo formal de tickets. O primeiro veio por e-mail (Outlook), pedindo a inclusão de monitoramento com OpenTelemetry, descrito como padrão obrigatório para os produtos da empresa.
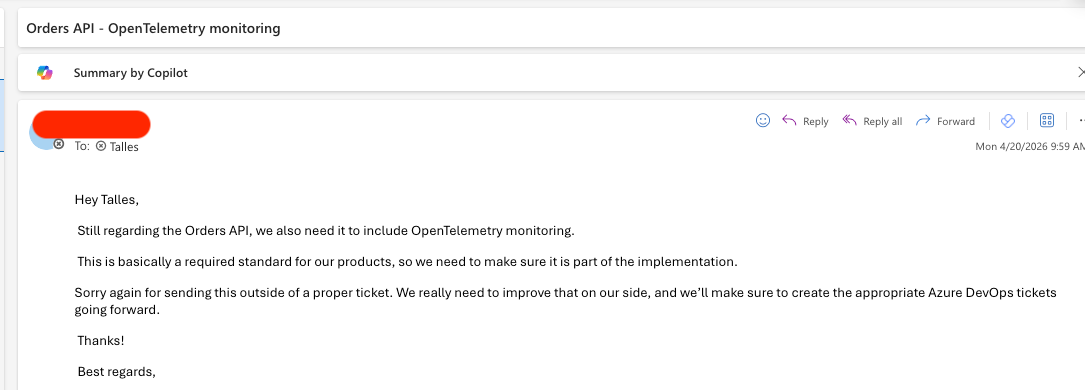
O segundo chegou por mensagem no Microsoft Teams, falando sobre a necessidade de aplicar um desconto sobre o valor total do pedido, calculado a partir da soma de preço vezes quantidade de cada item.
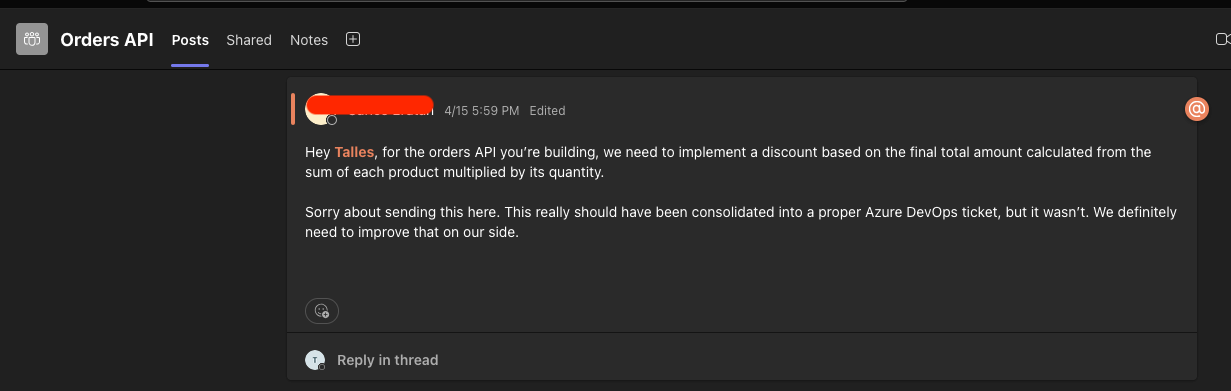
Esse tipo de comunicação informal acontece o tempo todo, e o desafio é garantir que esses requisitos não se percam e que sejam implementados respeitando as regras documentadas internamente. É exatamente aqui que a combinação de WorkIQ e Foundry IQ via MCP entra em cena.
Para configurar o WorkIQ MCP no VS Code, vamos adicionar o servidor à configuração do GitHub Copilot. O WorkIQ é instalado via pacote npm @microsoft/workiq, conforme detalhado na documentação oficial WorkIQ overview. Crie ou edite o arquivo .vscode/mcp.json na raiz do workspace adicionando o servidor:
{
"servers": {
"workiq": {
"command": "npx",
"args": ["-y", "@microsoft/workiq", "mcp"]
}
}
}Após salvar o arquivo, abra a paleta de comandos do VS Code, rode MCP: List Servers, selecione o workiq e faça o login com a conta corporativa do Microsoft 365 que tem acesso aos dados do tenant. A partir daí, as ferramentas do WorkIQ ficam disponíveis dentro do Copilot Chat em modo Agent.
Com o servidor ativo, o primeiro prompt útil é justamente recuperar os requisitos espalhados entre e-mails e o Teams. No Copilot Chat, em modo Agent, basta perguntar:
Use the WorkIQ MCP to list emails and Teams messages related to Order.Api.
I want to know which new requirements have been requested but are not yet implemented.
Show the full content of each item.O agente vai chamar a ferramenta ask_work_iq do servidor MCP, retornar o conteúdo do e-mail sobre OpenTelemetry e a mensagem do Teams sobre desconto, e consolidar isso em uma lista de tarefas a serem feitas no projeto.
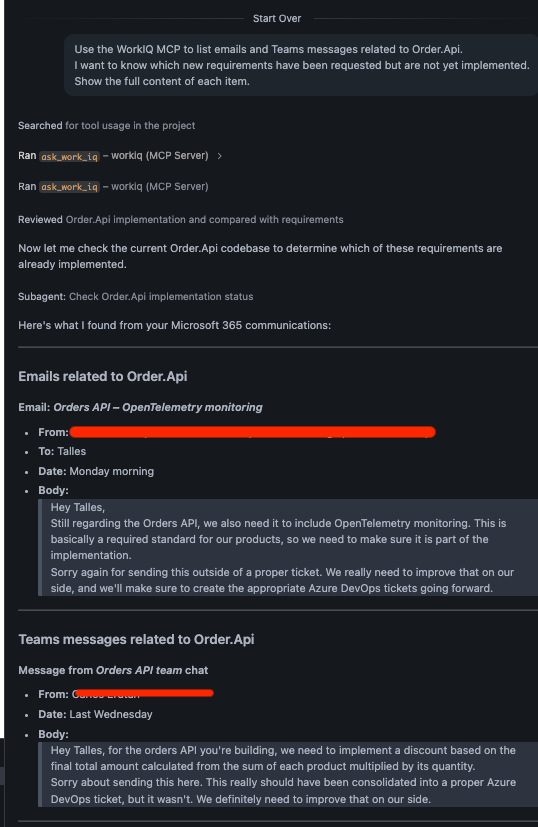
Uma vez que sabemos o que precisa ser feito, ainda falta a parte mais importante, que é descobrir como fazer dentro dos padrões da empresa. Os padrões e as regras de negócio vivem em documentos internos, e é aqui que entra o Foundry IQ. Antes de criar as bases de conhecimento, precisamos provisionar três coisas no Azure: um Storage Account com os documentos, um recurso do Microsoft Foundry com uma instância do modelo deployada e um recurso do Azure AI Search.
A primeira peça é o Storage Account. O Storage Account é o serviço de armazenamento unificado do Azure que abriga blobs, filas, tabelas e file shares. Para o nosso cenário, vamos usar containers de Blob Storage para hospedar os documentos. Crie o recurso pelo portal escolhendo o tier Standard com redundância LRS, que é mais que suficiente para esse caso. Os containers serão criados com acesso privado, que é o padrão do Azure, e o Azure AI Search vai acessar os blobs via identidade gerenciada, sem necessidade de expor os arquivos publicamente.
Dentro do Storage Account, crie dois containers. O primeiro chamado business-docs vai armazenar a documentação de regras de negócio, incluindo o documento que descreve como calcular o desconto.
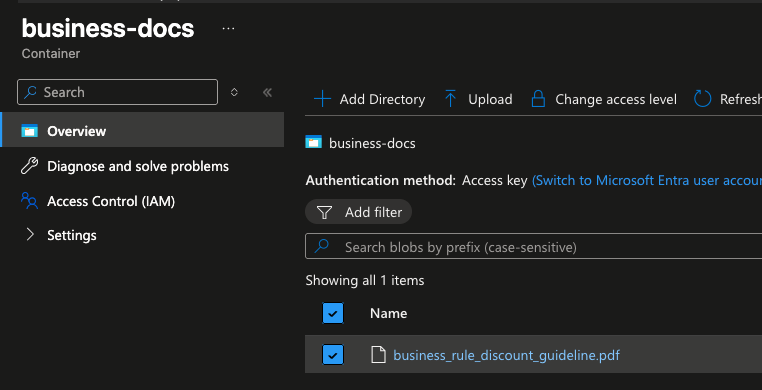
O conteúdo desse documento define a regra de desconto baseada no valor total do pedido, com faixas e percentuais que serão aplicados pela API.
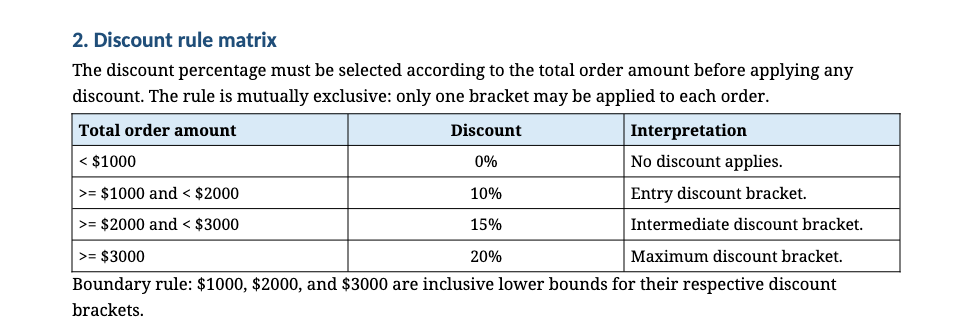
O segundo container, chamado docs, vai armazenar a documentação interna de padrões de desenvolvimento, especificamente o guia sobre como configurar OpenTelemetry nos serviços da empresa.
O conteúdo desse documento mostra como o SDK do OpenTelemetry é utilizado internamente pelos times da empresa, com exemplos concretos de instrumentação, nomes de pacotes adotados, configuração de exporters e convenções de naming seguidas nos projetos.
Com os documentos no lugar, a próxima peça é o Microsoft Foundry. Crie o recurso pelo portal informando nome, região e o tier desejado. O Foundry vai hospedar o modelo de linguagem que o Azure AI Search usa para consolidar as respostas das knowledge bases.
Após o provisionamento, acesse o Foundry e faça o deploy dos modelos gpt-4.1-mini e text-embedding-3-large (embeddings). O modelo gpt-4.1-mini é utilizado pelo Azure AI Search no processo de agentic retrieval, que é o mecanismo responsável por consolidar os chunks recuperados das knowledge sources em uma resposta coerente em linguagem natural. Para entender em detalhes como esse processo funciona dentro do Foundry IQ, recomendo a série de artigos que escrevi sobre o tema, começando pela parte 1 (https://www.azurebrasil.cloud/blog/foundry-iq-a-camada-de-conhecimento-dos-agentes-no-microsoft-foundry-parte-1/?wt.mc_id=MVP_407589).
Já o modelo text-embedding-3-large é utilizado para gerar os embeddings dos documentos que vão alimentar as knowledge sources, permitindo que o Azure AI Search faça a correspondência semântica entre as queries e os documentos indexados.
A terceira peça é o Azure AI Search. Crie o recurso escolhendo um tier compatível com agentic retrieval, lembrando de habilitar a identidade gerenciada para que ele consiga ler os blobs e chamar o modelo do Foundry.

Com a infraestrutura pronta, agora é hora de criar os knowledge sources. A documentação oficial cobre o passo a passo para criar uma knowledge source baseada em blob e baseada em web. Vamos criar três knowledge sources no total.
A primeira knowledge source, ks-business-logic-docs, aponta para o container business-docs do Storage Account e vai alimentar a base de regras de negócio.
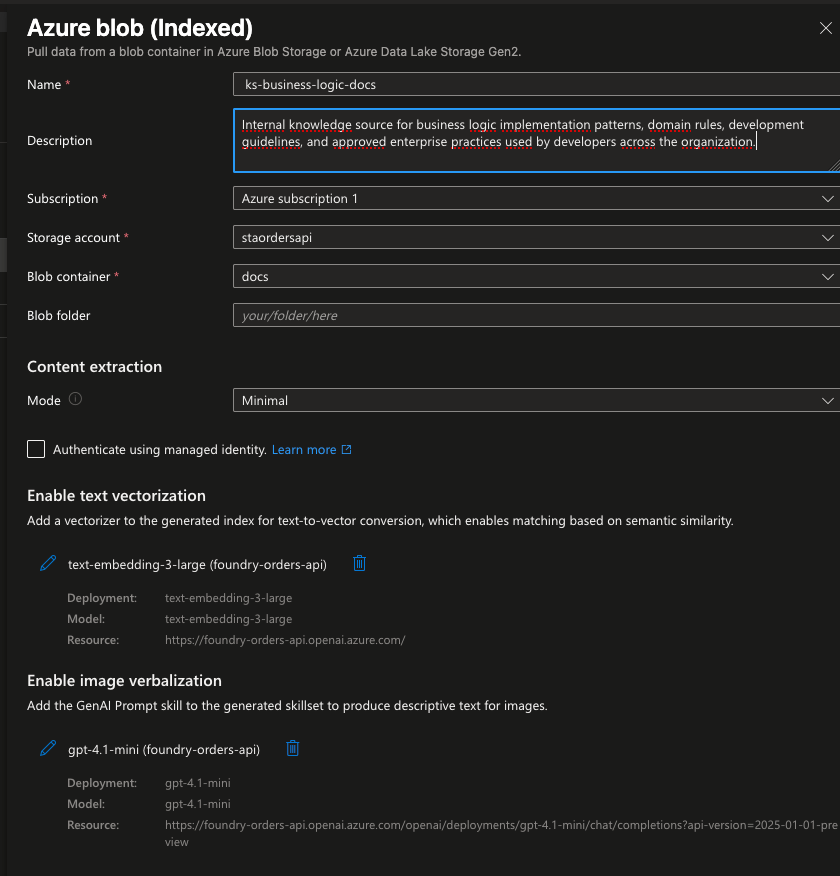
A segunda, ks-open-telemetry-internal-docs, aponta para o container docs e vai trazer a documentação interna de padrões de desenvolvimento.
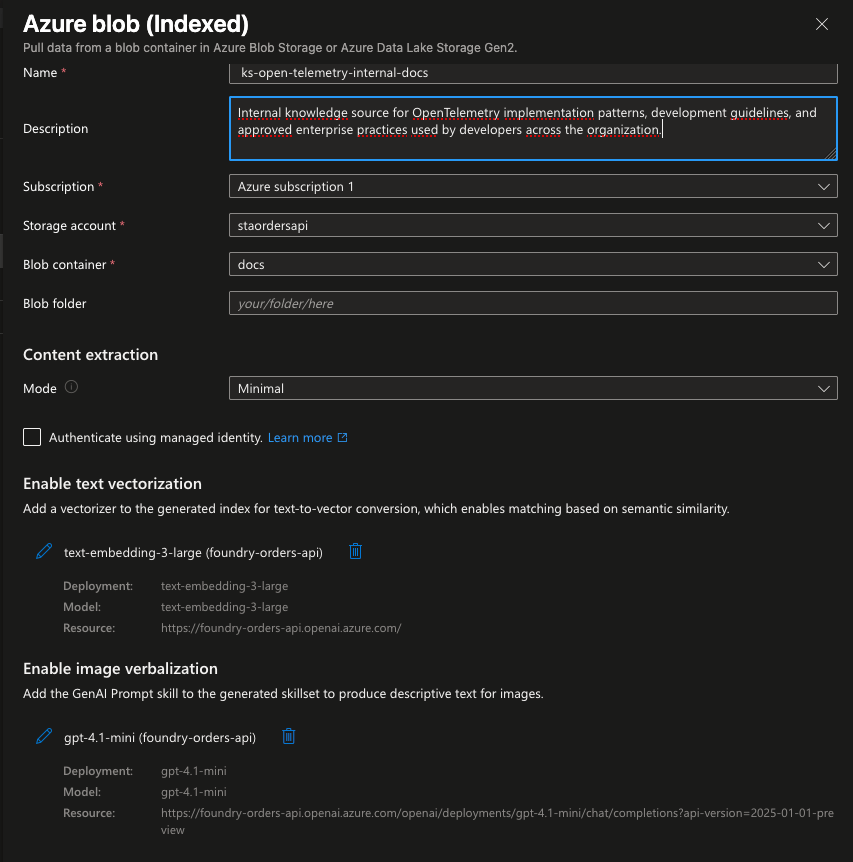
A terceira é uma knowledge source do tipo Web, integrada via Bing Search, chamada ks-open-telemetry-external-docs, conforme descrito no guia oficial de criação de knowledge sources baseadas em web . Ela vai indexar conteúdo público para complementar a documentação interna, com a lista de domínios permitidos restrita a learn.microsoft.com e opentelemetry.io, garantindo que apenas fontes oficiais sejam consideradas.
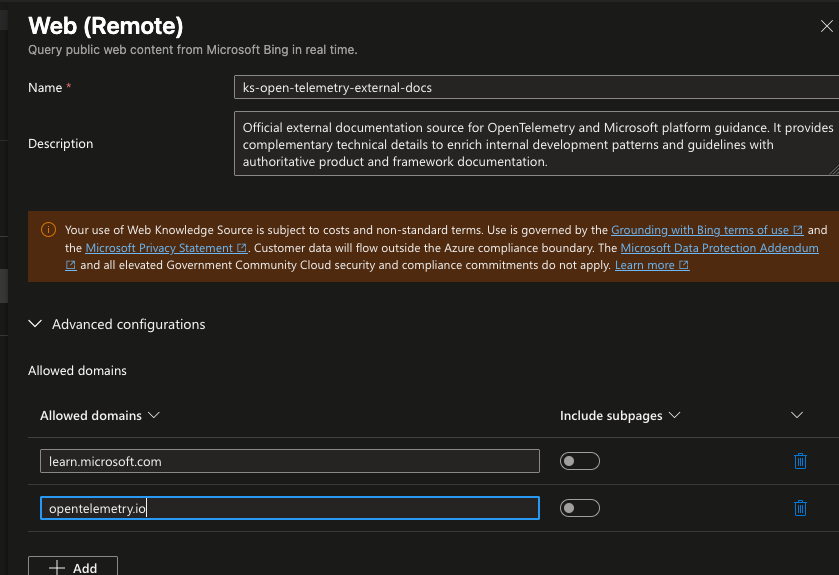
Com as fontes prontas, criamos as duas knowledge bases. A primeira, kb-business-logic-docs, agrupa apenas a knowledge source de regras de negócio.
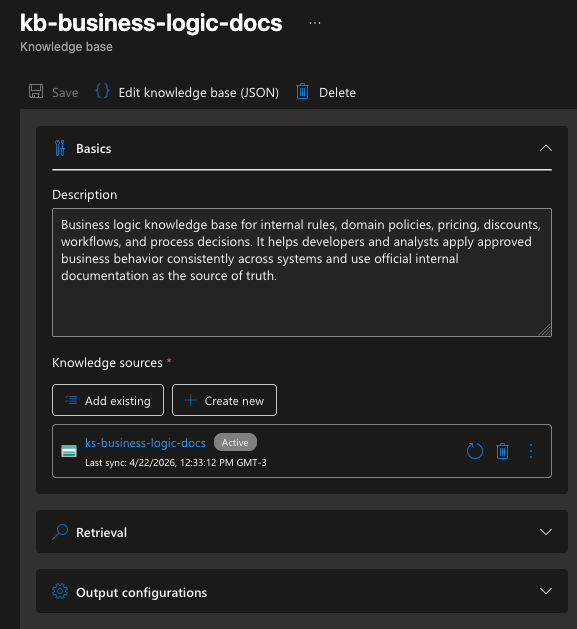
A segunda, kb-developer-patterns-and-official-docs, agrupa as duas knowledge sources de OpenTelemetry, a interna baseada em blob e a externa baseada em web crawl.
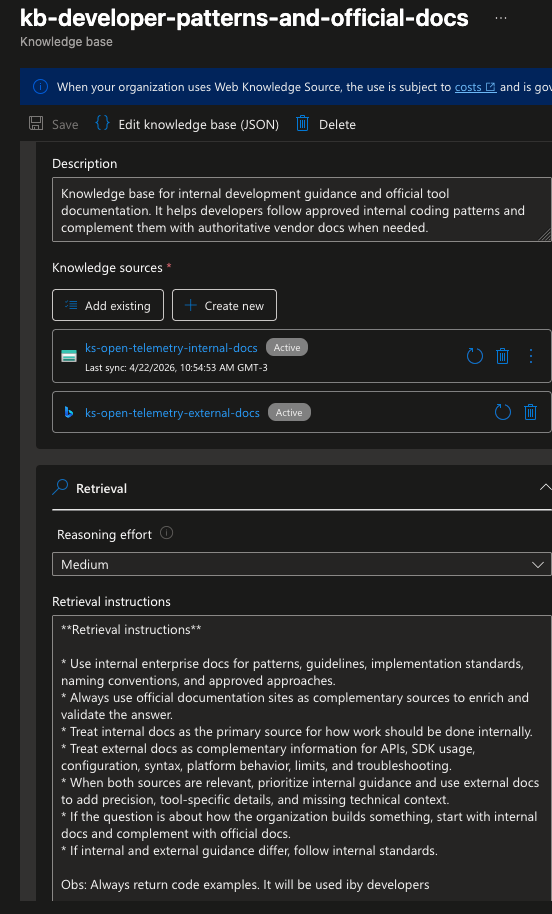
Em ambas as bases, configuramos o modelo de chat completion para apontar para o gpt-4.1-mini criado anteriormente no Microsoft Foundry, que é quem vai consolidar a resposta final a partir dos chunks recuperados.
Se quiser se aprofundar nas configurações do Azure AI Search, knowledge bases e knowledge sources, recomendo a documentação oficial, que cobre em detalhes o overview do Azure AI Search, o agentic retrieval, a criação de knowledge sources baseadas em blob e de knowledge sources baseadas em web. Para entender como tudo isso se encaixa dentro do Foundry IQ, a série de quatro artigos que escrevi cobre o serviço do início ao fim, passando por provisionamento, criação de knowledge sources e bases, configuração dos modelos e testes de consulta: parte 1, parte 2, parte 3 e parte 4.
Na próxima parte, vamos implementar o servidor MCP Docs.mcp em .NET 10 que expõe essas duas knowledge bases como ferramentas dentro do VS Code, conectar tudo ao GitHub Copilot e deixar o agente implementar os dois requisitos descobertos nessa parte. Até lá!





