
O cert-manager não era o problema, e a gente demorou pra aceitar
Certificado SSL autoassinado em produção. Cliente nervoso. Ingress respondendo com aquele erro vermelho no browser que faz qualquer pessoa de negócio ligar pra TI em pânico.

A gente chegou pra investigar achando que seria rápido — cert-manager, certo? Deleta o certificate, espera o ACME resolver, toma um café. Dez minutos, no máximo.
Foram horas. E o problema nunca foi o cert-manager.
O cenário
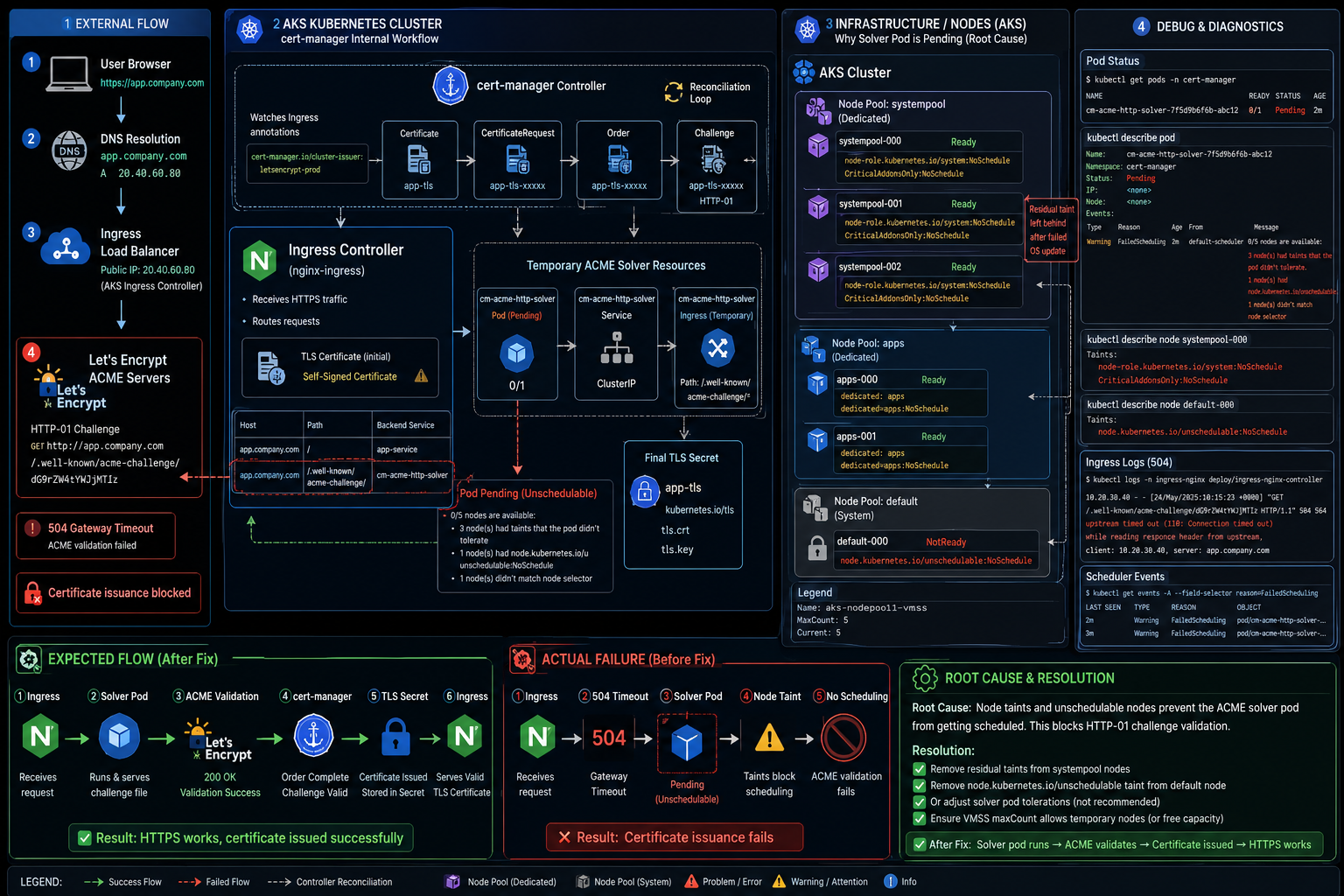
O cliente rodava um cluster AKS com uma organização bem definida de workloads. Todos os Worker Nodes possuíam Taints e Labels — uma classificação por tipo de aplicação. Aplicações de backend iam pra um grupo de máquinas, jobs de processamento pra outro, e quando nenhuma Taint era atendida, existia um grupo "default" — um ScaleSet do AKS que recebia tudo que não se encaixava em lugar nenhum.
O Ingress do serviço em questão estava com um certificado autoassinado. Isso acontece com mais frequência do que as pessoas admitem: alguém cria o Ingress, o DNS ainda não está apontado no registrar, o cert-manager tenta emitir o certificado via ACME, falha na validação HTTP-01 porque o domínio não resolve, e o cluster fica com uma SSL autoassinada. O tempo passa, alguém aponta o DNS, mas o certificado autoassinado já está lá — e o cert-manager não tenta de novo sozinho.
Na prática, o cert-manager fez o trabalho dele. O problema foi o timing.
A primeira tentativa — simples demais pra funcionar
Deletamos o recurso Certificate do namespace. A lógica era direta: sem o certificate, o cert-manager deveria detectar a ausência via o Ingress annotation, criar um novo CertificateRequest, e o ACME solver faria o challenge HTTP-01 com o DNS já apontado.
Mas o novo certificado não veio.
Fizemos um curl direto na URL do challenge — aquele path /.well-known/acme-challenge/<token> que a Let's Encrypt bate pra validar o domínio. Enquanto isso, abrimos os logs do Ingress Controller pra acompanhar a requisição chegando. O curl voltou um 504 Gateway Timeout. O Ingress estava recebendo a request, tentando rotear pro backend do solver, e não conseguia — porque o backend simplesmente não existia.
Fomos olhar os pods. O cm-acme-http-solver — aquele pod temporário que o cert-manager sobe pra responder o challenge da Let's Encrypt — estava Pending. Sem evento de schedule. Sem node atribuído.
Isso fazia sentido quando você olhava a arquitetura do cluster. Todos os nodes tinham Taints. O solver pod não tinha nenhuma Toleration configurada — ele simplesmente não tinha permissão pra rodar em nenhum Worker Node classificado.
OK. Problema claro. Solução clara. Certo?
Configurando o Helm — a solução que deveria funcionar
Fomos no Helm chart do cert-manager e adicionamos tolerations e nodeAffinity em todos os componentes:
# values.yaml do cert-manager
tolerations:
- key: "workload-type"
operator: "Exists"
effect: "NoSchedule"
webhook:
tolerations:
- key: "workload-type"
operator: "Exists"
effect: "NoSchedule"
cainjector:
tolerations:
- key: "workload-type"
operator: "Exists"
effect: "NoSchedule"
startupapicheck:
tolerations:
- key: "workload-type"
operator: "Exists"
effect: "NoSchedule"
Deploy. Todos os pods do cert-manager — controller, webhook, cainjector, startupapicheck — rodando. Tudo verde.
Deletamos o certificate de novo. Esperamos. O cm-acme-http-solver... continuou Pending.
O problema é que o Helm chart do cert-manager não expõe configuração de tolerations para o solver pod. Esse pod é criado dinamicamente pelo controller durante o challenge ACME, e a configuração dele não passa pelos values do Helm. É uma limitação conhecida do chart — que ninguém parece ter urgência em resolver. Você descobre depois de configurar tudo certinho nos outros componentes.
Na prática, você pode configurar o cert-manager inteiro pra rodar em nodes com Taints. Mas o pod que realmente precisa subir pra emitir o certificado? Esse não tem como configurar pelo chart.
A alternativa — escalar o ScaleSet padrão
Se o solver não aceita Toleration via Helm, ele precisa de um node sem Taint. O único lugar no cluster sem Taints específicas era o ScaleSet padrão — aquele grupo "default" que recebia workloads órfãos.
A ideia era simples: garantir que esse ScaleSet tivesse capacidade pra agendar o solver pod. Fomos verificar.
Foi aí que paramos de olhar pro cert-manager.
O ScaleSet padrão tinha maxCount: 3. E já tinha 3 nodes rodando. Capacidade máxima atingida. Faz sentido — o solver não consegue agendar porque não tem máquina disponível. Vamos aumentar o maxCount, deixar o autoscaler subir um node novo, e pronto.
Mas antes de mudar qualquer coisa, a gente olhou os nodes desse ScaleSet com mais atenção. E aí apareceu o problema real.
O que realmente aconteceu
O AKS tem um processo de atualização automática de OS nos Worker Nodes. O comportamento padrão é um Rolling Update: o AKS sobe uma nova Worker Node com o OS atualizado, drena os pods da Worker Node antiga, migra tudo pra nova, e desliga a antiga. Durante esse processo, temporariamente você tem N+1 nodes — um a mais que o normal.
O ScaleSet padrão estava configurado com maxCount: 3. Já tinha 3 nodes. Quando o processo de atualização tentou subir a 4ª máquina temporária — não conseguiu. Hard limit. O ScaleSet não permitiu ultrapassar o máximo.
E aqui é onde a coisa ficou feia.
O processo de atualização não completou corretamente. A Worker Node que deveria ser atualizada ficou presa entre o OS antigo e o novo. O AKS aplicou uma Taint nessa node — comportamento esperado durante o drain — mas como a atualização não finalizou, a Taint nunca foi removida.
Resultado: uma Worker Node no ScaleSet padrão — que era pra ser o grupo sem Taints restritivas — estava com uma Taint que impedia o scheduling de pods. E o cm-acme-http-solver, que dependia justamente de um node sem Taints pra ser agendado, olhava pra esse node e via a Taint. Olhava pros outros nodes classificados e não tinha Toleration. Ficava Pending. Pra sempre.
kubectl describe node aks-default-12345678-vmss000002
Taints: node.kubernetes.io/unschedulable:NoSchedule
Uma Taint residual de um update de OS que falhou silenciosamente.
A correção
Duas ações:
- Aumentamos o
maxCountdo ScaleSet padrão pra dar margem pro Rolling Update funcionar sem bater no limite - Removemos a Taint residual da Worker Node afetada
kubectl taint nodes aks-default-12345678-vmss000002 node.kubernetes.io/unschedulable:NoSchedule-
O solver pod subiu. O challenge HTTP-01 completou. O certificado foi emitido. O Ingress parou de mostrar SSL autoassinada.
O que a gente aprendeu — de verdade
A gente passou horas debugando cert-manager. Configuramos Helm values. Lemos issues no GitHub do chart. Discutimos limitações do solver. E o problema era um node com uma Taint fantasma deixada por um update de OS que não completou.
Três lições concretas:
Primeiro — o maxCount de qualquer ScaleSet no AKS precisa ter margem pra operações de manutenção. Se você tem 3 nodes e o máximo é 3, o Rolling Update não tem espaço pra trabalhar. Coloque pelo menos N+1 como máximo, onde N é a quantidade de nodes que você precisa em operação normal.
Segundo — updates automáticos de OS que falham nem sempre geram alertas visíveis. O AKS tenta, falha silenciosamente na expansão do ScaleSet, e deixa o node num estado parcialmente atualizado com Taints residuais. Monitore o estado dos nodes depois de janelas de manutenção. Um kubectl get nodes -o wide e um kubectl describe node nos nodes do ScaleSet padrão depois de updates pode te poupar horas de investigação no lugar errado.
Terceiro — quando um pod fica Pending sem eventos de scheduling, o reflexo é olhar o pod, o deployment, o controller. Mas o problema pode estar no node. Se os Pods parecem corretos mas não agendam, olhe os nodes. Verifique Taints. Verifique capacidade. Verifique se algum processo de manutenção deixou sujeira.
Conclusão
A gente deletou certificate, configurou Helm, leu documentação, discutiu limitação de chart, planejou escalar o ScaleSet — e o problema era uma Taint que sobrou de um update que não completou.
Nenhuma ferramenta de observabilidade apontou. Nenhum alerta disparou. Foi um kubectl describe node que resolveu.
Só mais um dia na vida de DevOps.





