Débito cognitivo
Parabéns, seu time não entende mais o que construiu

Débito técnico. A metáfora que virou muleta de toda retrospectiva. Todo mundo fala. Todo mundo reclama. Todo mundo finge que vai pagar.
Mas enquanto você fica debatendo se aquele // TODO: refactor later de 2019 é dívida técnica ou arqueologia, tem um débito silencioso corroendo seu time por dentro. Não está no código. Está na cabeça das pessoas.
Chama-se débito cognitivo. E se você trabalha com LLMs gerando código, pode ter certeza: está acumulando com juros compostos.
Martin Fowler compartilhou recentemente um fragmento sobre um paper da Margaret-Anne Storey que organiza saúde de sistemas em três camadas. Quando li, não achei a ideia nova. Achei que finalmente alguém nomeou o que eu vejo acontecer em times desde que coding agents viraram mainstream.
Vamos lá. Neste artigo vamos cobrir: o que é débito cognitivo, como ele difere de débito técnico, por que LLMs aceleram o problema, o que a teoria de cognição tri-sistêmica muda na conversa, e o que você precisa fazer antes que seu time vire refém do próprio código.
Três dívidas — e só uma está no seu linter
Três dívidas. Débito técnico, débito cognitivo e débito de intenção.
Se você não sabe — ou chegou na área há pouco tempo — essa discussão de débito técnico existe há uns 30 anos. Ward Cunningham cunhou o termo em 1992. Acredite se quiser.
E agora a Margaret, no paper Three Layers of System Health, aponta que débito técnico é apenas uma das três camadas. E, segundo ela, não é a mais perigosa.
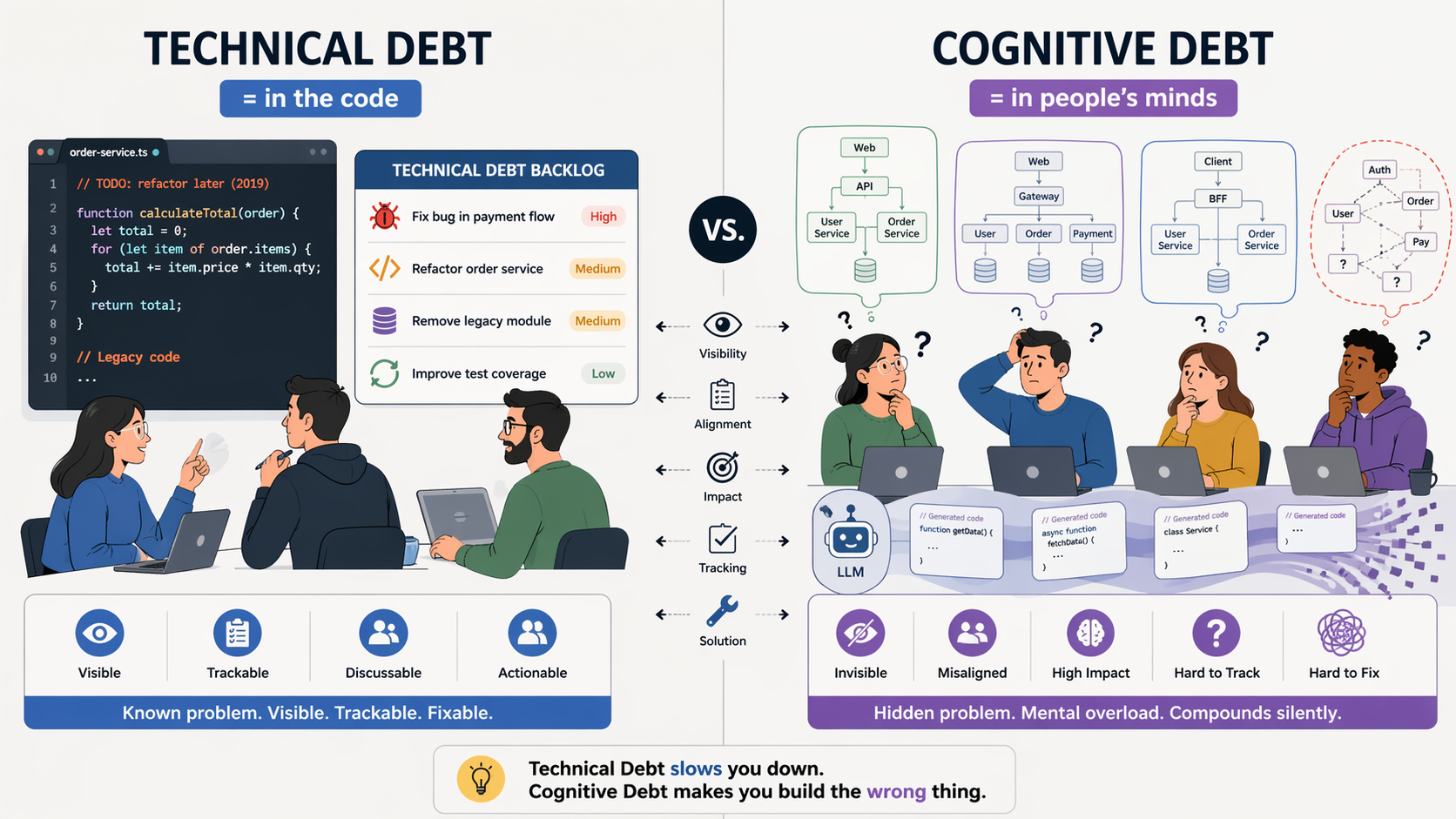
Débito técnico é o que todo mundo conhece. Vive no código. São decisões que comprometem a capacidade de mudar o sistema no futuro. Sabe aquele if com 47 condições que foi feito pra entregar mais rápido e que não tem nenhum teste? É isso. Uma espécie de limite sobre como o sistema pode mudar.
Débito cognitivo é o vilão desse artigo. Vive nas pessoas. Acumula quando o entendimento compartilhado do sistema se dissipa. O bicho pega aqui — a Storey descreve como um limite sobre como o time raciocina sobre mudanças. Não é sobre o código ser ruim. É sobre ninguém saber o que o código faz.
Débito de intenção é o terceiro fantasma. Acumula quando os objetivos e restrições que deveriam guiar o sistema estão mal capturados ou mal mantidos. Sabe quando o propósito do sistema se perdeu? Ninguém mais sabe o que queria construir. As ADRs não existem. Os requisitos estão numa conversa de Slack de 2023. O "porquê" evaporou.
As três categorias interagem entre si. Débito técnico ignorado vira débito cognitivo — ninguém refatora o que ninguém entende. Débito de intenção ausente vira débito técnico que ninguém corrige porque ninguém sabe a intenção original. Isso se retroalimenta. E vai piorando em silêncio.
"Mas meu time entende o sistema" — não, não entende
Deixa eu contar uma coisa que tenho certeza que você já viu. Se não viu, vai ver.
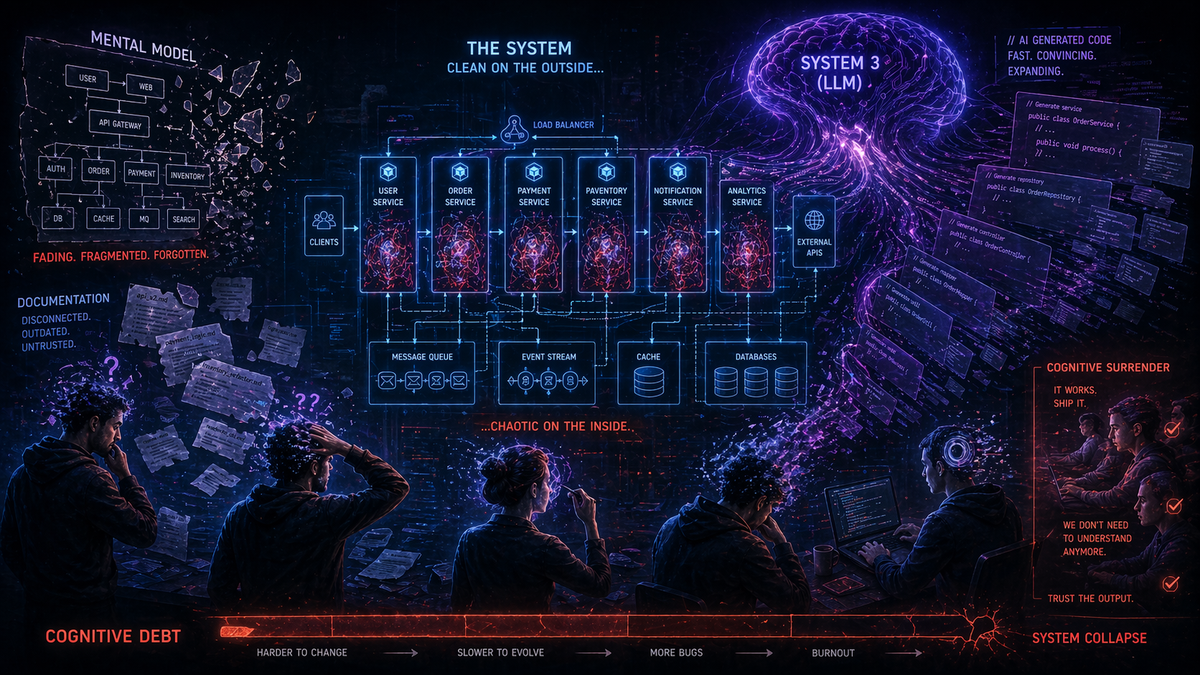
Time de oito devs. Sistema relativamente complexo — microsserviços, mensageria, APIs internas, integração com fornecedores. Todo mundo "conhecia" o sistema. Os seniors estavam lá desde o início. Os bugs eram resolvidos. O deploy rolava toda semana. Normal.
Mas os chefes pressionaram, deram chicotadas, foram escrotos. Rebelião aconteceu. Três seniors saíram em três meses.
Sabe o que aconteceu?
Ninguém sabia por que o serviço de reconciliação rodava duas vezes — uma à meia-noite, outra às 6h. Ninguém sabia explicar o retry com backoff que tinha no client do fornecedor X. Ninguém lembrava por que o endpoint /v1/payments existia se já tinha o /v2/payments. Uma das aplicações tinha um trigger na infra que reiniciava ela todo dia às 6 da manhã — e ninguém sabia por quê.
O código funcionava. Testes passavam. Nenhuma ferramenta de análise estática ia sinalizar nada.
Mas o entendimento compartilhado se perdeu. O time todo era importante — cada pessoa carregava pedaços do contexto. Mesmo com a entrada de novos devs, levaria meses, quem sabe anos, até o time voltar ao mesmo patamar sobre tomar decisões relacionadas ao sistema como um todo. O conhecimento tinha evaporado.
Isso é débito cognitivo. Não está no código. Está na lacuna entre o que o sistema faz e o que as pessoas entendem que ele faz.
E se você está se perguntando o que isso tem a ver com IA — aqui é onde LLMs entram na conversa.
Nesse exemplo, o débito cognitivo se acumulava organicamente. Rotatividade do time, crescimento desordenado, falta de documentação. Processo natural. Lento.
Agora LLMs funcionam como catapulta. A velocidade de produção de código que ninguém entende multiplicou quantas vezes?
LLMs como catalisadores de débito cognitivo
Como a banda está tocando agora? Você que é dev acha que está enganando alguém? Todo mundo sabe que você usa um agent de código.
O agent gera 200 linhas. Você revisa superficialmente. "Funciona, testes passam" — mergea o PR e bora pro bar.
Mas você não escreveu aquele código. E o caminho da escrita de código tem etapas mentais:
- Qual é o problema de negócio que vou resolver?
- Quais são as regras?
- Qual design pattern faz sentido aqui?
- Quebro esse objeto em mais objetos?
- Como esses objetos se relacionam entre si?
Cabem mais perguntas aí. E nenhuma delas foi você quem respondeu. Foi terceirizado. Mesmo que você tenha feito esse debate com a LLM, há nuances que se perdem no meio do caminho — decisões de design que o agent tomou sem te consultar, abstrações que ele criou porque apareciam com frequência no dataset de treinamento, não porque faziam sentido no seu contexto.
Na teoria, LLMs aceleram a entrega. Na prática, aceleram a entrega de código que ninguém entende.
A Storey é direta no paper:
Cognitive debt lives in people. It accumulates when shared understanding of the system erodes faster than it is replenished.
O débito cognitivo está nas pessoas. Não no repositório. Não no CI/CD. Nas pessoas.
Agora pense: o que acontece quando o volume de código novo triplica porque LLMs geram rápido, mas ninguém de fato sabe o que tem ali dentro?
Entrega acelera. Compreensão não acompanha. Esse gap entre as duas? Débito cognitivo.
Pelo menos o gerente está feliz, né.
Eu mesmo já caí nesse problema. Fiz uma feature com LLM e uma semana depois percebi que tinha vários gaps de negócio. Estava aqui no meu computador codando como se não houvesse amanhã e construí perfeitamente a coisa errada. Foi legal fazer. Mas construir a coisa errada rápido continua sendo construir a coisa errada.
Sistema 3: quando a IA vira muleta cognitiva
A Margaret classificou os tipos de débito. Mas Shaw e Nave foram mais fundo no mecanismo psicológico por trás do problema.
O ponto de partida é um conceito de 2011, popularizado pelo Kahneman. A ideia de que temos dois sistemas cognitivos.
Sistema 1 é a intuição. Decisões rápidas, quase inconscientes. "Esse código parece certo." "Esse pattern eu já vi." É barato cognitivamente.
Sistema 2 é a deliberação. Quando você para, pensa, analisa trade-offs, questiona premissas. É caro. É lento. E é exatamente ele que diferencia um senior de um junior — não a velocidade de digitação, mas a profundidade de análise. Sabe aquele problema que quando chega no final do dia você está exausto? É o Sistema 2 que gastou.
Shaw e Nave, no paper Adding LLMs to Kahneman's Two-System Model, propõem que agora, com LLMs, temos um Sistema 3 — o raciocínio artificial externo.
A consequência direta do Sistema 3 é o que eles chamam de rendição cognitiva (cognitive surrender). Os humanos param de pensar na resposta. Aceitam o que a IA deu. Assumem que é verdade. Bypass direto no Sistema 2.
Mas o paper faz uma distinção que importa:
Cognitive surrender não é cognitive offloading.
Parece parecido. Não é.
Imagina um dev que usa LLM pra gerar um boilerplate de configuração que ele já fez 50 vezes. Isso é offloading. Delegou a tarefa. Ele sabe o que está ali, sabe validar, sabe quando está errado. Delegou porque já domina aquilo.
Agora pega outro dev que usa LLM pra projetar uma arquitetura de mensageria que ele nunca viu na vida. A LLM implementa. Ele olha o resultado, aceita porque "parece fazer sentido", e mergea o PR sem questionar cada decisão. Até porque não tem base pra isso. Isso é surrender. Rendição.
E é nesse cenário que o débito cognitivo do time aparece com força. Agora existe código em produção que ninguém do time entende de verdade.
Eu achava que débito técnico era a principal métrica de saúde de um codebase. Estava errado. Débito técnico é visível — ferramentas pegam, métricas mostram, refactoring resolve. Débito cognitivo é invisível até o momento em que alguém precisa mudar algo e descobre que ninguém sabe como o sistema funciona.
Mas pelo menos o gerente está felizão. E quem assinou o PR foi você.
O que quebra: verificação é o novo gargalo
O que acontece em times que adotam agents sem repensar o processo:
O volume de código cresce. LLMs são rápidos, isso é fato. O volume de PRs cresce — mais código, mais merges, mais ruído. A profundidade de review cai. Ninguém lê PR de 400 linhas gerado por IA com o mesmo cuidado que lê 40 linhas escritas por um colega. O código do colega dá pra fofocar o quão idiota alguém da equipe é. Já o código da LLM é chato de criticar. E o entendimento compartilhado do sistema vai pro espaço. Cada PR mergeado sem compreensão real é débito cognitivo acumulado.
E o pior: quando algo quebra, o tempo de correção explode. Porque ninguém sabe o que aquele código faz direito. Debugar vira pesadelo.
Ajey Gore, citado no artigo do Fowler, diz que a solução é reorganizar o time pra verificar código, não produzir código.
Sinceramente? Duvido.
Entender uma lógica demora mais do que construir uma lógica. Isso não é só achismo meu — já vi referências sobre isso, acho que Uncle Bob fala disso em Clean Code, ou foi no Refactoring do próprio Fowler. Enfim, o ponto é: se produzir código ficou barato, a verificação ficou proporcionalmente mais cara. E não estou convencido de que simplesmente realocar pessoas resolve.
Mas que a verificação precisa melhorar, precisa.
O que mudar — antes de virar refém
Agora, indo pros meus achismos sobre o que vem pela frente.
Primeiro: esqueça débito técnico como o grande vilão. Débito técnico ainda existe, mas perdeu o protagonismo. A IA escreve código decente. Às vezes escreve melhor que muito "senior" de dois anos por aí. O débito que vai machucar é o cognitivo — e ninguém sabe como medir.
Por quê? Porque antes de falar em débito cognitivo, precisa pensar na estrutura de como a gente opera. Somos pressionados por números desde que nascemos. Postou foto? Quantos likes. Entregou? Qual o lead time. Fez deploy? Quantas vezes por semana.
Esse ambiente de "entrega logo, depois a gente pensa" sempre atropelou as coisas. Se atropela débito técnico — que a gente minimamente consegue medir — tu acha mesmo que não vai atropelar algo que ninguém vê?
Quer saber se tem débito cognitivo no seu time? Faça o teste simples: chama qualquer dev e pede pra explicar como funciona um fluxo crítico do sistema. Sem olhar o código. Se a explicação não é coerente, você tem débito cognitivo. Faça isso regularmente — não como pegadinha, como diagnóstico.
Segundo: code review. Já está sob pressão. E vai piorar. Porque quando a coisa estoura, chega a hora da caça às bruxas. O gerente pergunta: quem fez isso? O dev responde: "Fiz com a IA que a empresa pagou pra usar. Quem aprovou foi fulano."
Vai ter gente defendendo que quem escreve código é a IA e o humano precisa saber tintim por tintim antes de dar merge. Convenhamos? Duvido que funcione assim na prática.
Terceiro, e diria que o mais importante: saiba a diferença entre offload e surrender. Use agents para aquilo que você já sabe fazer e quer automatizar. Essa linha é um pouco nebulosa — com IA, o que você sabe e o que você não sabe pode passar despercebido — mas já é uma boa reflexão a ter. Se está delegando uma decisão que não entende, essa treta volta.
E por fim acho que a gente vai observar uma coisa engraçada: conceitos antigos do agile vão voltar. Não porque ficou "cool", mas porque a solução já estava aí e a gente ignorava.
Pair programming com agent. Um "codando" e o outro acompanhando — mas com um humano de verdade no papel de "entende o que está acontecendo". Não por nostalgia. Porque precisa.
Mais TDD e BDD, porque se o código ficou barato, o que fica caro é errar o comportamento. Se o agent escreve o código e os testes já existem, você tem verificação automatizada. Se o agent escreve o código e testes não existem — parabéns, agora é código misterioso em produção sem rede de segurança.
E uma pressão maior por arquiteturas mais robustas e monólitos mais bem pensados. Se produzir código virou commodity, o diferencial volta a ser decisão, modelagem e limites bem definidos.
Fim de história
Ferramentas pegam débito técnico. Débito cognitivo ninguém mede — vive na cabeça das pessoas, não no repositório.
Com LLMs gerando código na velocidade que geram, o débito cognitivo vai se tornar a dívida mais cara da indústria de software. Não porque LLMs sejam ruins — são ferramentas poderosas. Mas porque ferramentas poderosas nas mãos de quem não entende o que está construindo produzem sistemas que ninguém consegue manter.
Shaw e Nave chamaram de cognitive surrender. A rendição silenciosa do pensamento crítico. A ironia é que a ferramenta que promete aumentar sua produtividade pode estar atrofiando exatamente a habilidade que te faz útil: pensar sobre o que você está construindo.
Referências:
- Margaret-Anne Storey, Three Layers of System Health
- Shaw & Nave, Adding LLMs to Kahneman's Two-System Model
- Ajey Gore, The Expensive Thing
- Martin Fowler, Fragments: April 2





