
Observabilidade avançada para GPU e inferência no Azure
Métricas, gargalos e custo em workloads de IA em produção

Introdução
Em workloads de Inteligência Artificial, observar apenas CPU, memória e disco não é suficiente. GPUs têm comportamento próprio, gargalos específicos e custo elevado. Sem observabilidade adequada, é comum ver ambientes caros, instáveis e difíceis de escalar.
Em produção, os problemas mais comuns são:
- GPUs subutilizadas
- inferência lenta sem causa aparente
- filas invisíveis
- custos altos sem correlação com valor entregue
A observabilidade de GPU e inferência precisa ser tratada como parte da arquitetura, não como um ajuste posterior.
Neste artigo você vai aprender:
- quais métricas de GPU realmente importam
- como observar GPU em VMs e AKS
- onde surgem os gargalos reais de inferência
- como usar p50, p90 e p99 corretamente
- como conectar performance e custo em ambientes multi-cluster
Por que observabilidade de GPU é diferente
GPU não se comporta como CPU.
Problemas comuns em produção:
- GPU com baixo uso, mas alto custo
- GPU saturada por memória, não por compute
- gargalo de I/O mascarando uso de GPU
- inferência lenta mesmo com GPU ociosa
Sem métricas específicas, decisões de escala tendem a ser erradas.
Regra prática.
Se você não mede GPU corretamente, você está pagando para adivinhar.
Métricas essenciais de GPU
Métricas de compute
- GPU utilization
- SM occupancy
- active cycles
Indicam se o modelo está realmente usando o poder de processamento da GPU.
Métricas de memória
- GPU memory used
- GPU memory free
- memory bandwidth
Muitos modelos sofrem mais por falta de memória do que por compute.
Métricas térmicas e de energia
- temperature
- power draw
- throttling events
Quedas silenciosas de performance geralmente aparecem aqui primeiro.
Observabilidade de GPU em VMs no Azure
Para VMs com GPU, a arquitetura mais comum envolve:
- NVIDIA DCGM
- Azure Monitor Agent
- Log Analytics
- Azure Workbooks
Fluxo típico:
- DCGM coleta métricas da GPU
- Azure Monitor Agent envia os dados
- Log Analytics armazena
- Workbooks exibem dashboards
Boas práticas:
- coletar métricas por VM
- usar tags por workload
- coletar em intervalos menores para inferência
Observabilidade de GPU no AKS
AKS adiciona outra camada de complexidade.
Componentes essenciais:
- NVIDIA Device Plugin
- DCGM Exporter
- Container Insights
- métricas customizadas
Métricas importantes:
- uso de GPU por pod
- memória de GPU por container
- pods pendentes por falta de GPU
- tempo de fila de inferência
Boas práticas:
- node pools GPU dedicados
- namespaces separados
- métricas agregadas por modelo
Gargalos reais de inferência
Na prática, a GPU raramente é o único gargalo.
Problemas frequentes:
- fila de requisições
- cold start do modelo
- carregamento lento de pesos
- contenção de memória GPU
- limitação de rede
- serialização excessiva
É por isso que observar apenas GPU utilization não é suficiente.
Entendendo p50, p90 e p99 na inferência de IA
Médias escondem problemas. Inferência apresenta distribuição assimétrica. A maioria das requisições é rápida, mas uma pequena parcela pode ser extremamente lenta.
O que são percentis
- p50. 50 por cento das requisições respondem até esse tempo. Representa a experiência típica.
- p90. 90 por cento das requisições respondem dentro desse tempo. Mostra comportamento sob carga.
- p99. 99 por cento das requisições respondem dentro desse tempo. Revela outliers e instabilidade.
Regra prática: Usuários reclamam por causa do p99, não do p50.
Distribuição de latência na prática
No diagrama:
- p50 concentra a maioria das requisições
- p90 já mostra degradação
- p99 evidencia a cauda longa que impacta SLA
Por que p99 é crítico em IA
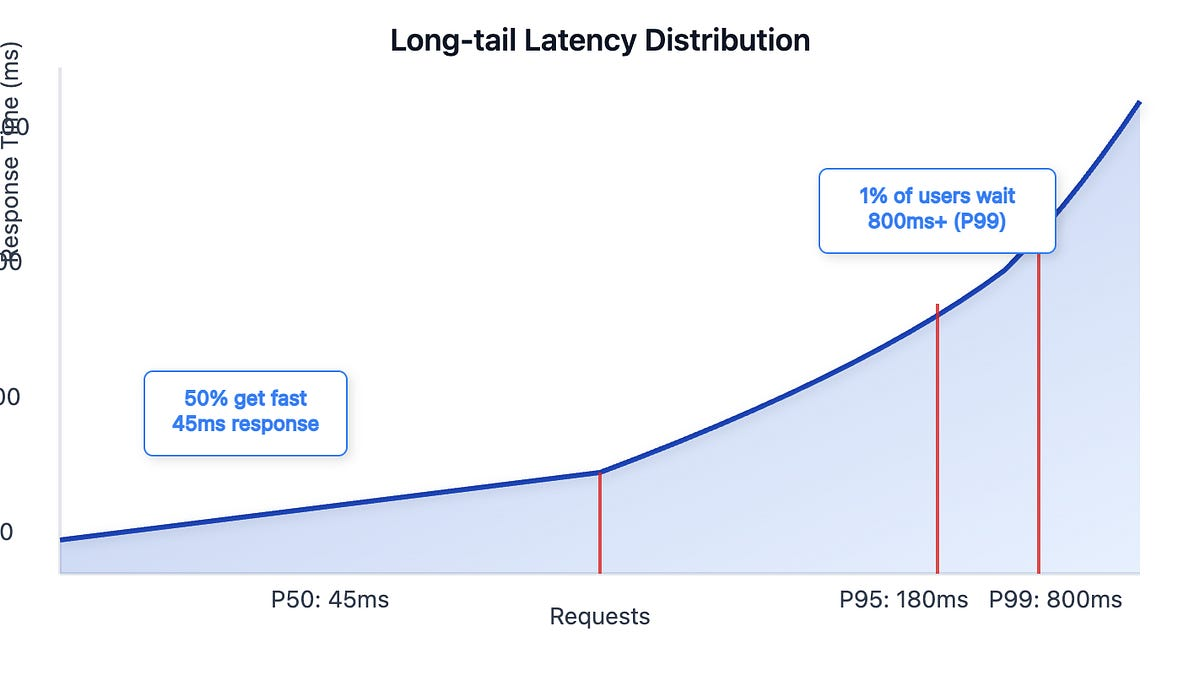
Exemplo realista:
- p50. 45 ms
- p90. 170 ms
- p99. 800 ms
Se você olhar apenas p50, tudo parece saudável.
O p99 mostra que o sistema não é confiável sob carga real.
O que normalmente causa p99 alto
Na maioria dos casos, p99 elevado não é culpa direta da GPU.
Causas comuns:
- cold start do modelo
- leitura de pesos do storage
- fila antes da GPU
- contenção de memória
- pods aguardando GPU livre
- limitação de rede
Conectando observabilidade e custo
GPU é cara. Cada minuto desperdiçado importa.
Boas práticas:
- custo por modelo
- custo por cluster
- custo por requisição
- custo por GPU-hour
Combine:
- métricas de uso real
- tags por workload
- dados do Azure Cost Management
Resultado: Você sabe exatamente quanto custa cada modelo em produção.
Multi-cluster e observabilidade centralizada
Em AKS multi-cluster, observar clusters isoladamente não funciona.
Arquitetura recomendada:
- Log Analytics central
- métricas consolidadas
- dashboards por cluster
- alertas globais
Alertas importantes:
- GPU abaixo de 20% por período prolongado
- GPU acima de 90% de forma contínua
- fila de inferência crescente
- custo fora do padrão
Alertas que realmente importam
Evite alertas genéricos.
Alertas úteis:
- p99 acima do SLA
- GPU ociosa com fila crescente
- pods pendentes por falta de GPU
- falha de alocação de GPU
- eviction de Spot durante treino
Alertas ruins:
- picos pontuais
- métricas sem impacto real
- médias sem contexto
Conclusão
Observabilidade avançada para GPU e inferência não é luxo.
É o que separa plataformas de IA eficientes de ambientes caros e instáveis.
Resumo final:
- GPU exige métricas próprias
- inferência precisa de visão fim a fim
- p99 indica estabilidade real
- custo deve ser correlacionado com uso
- multi-cluster exige observabilidade central
Infraestrutura madura de IA no Azure mede antes de escalar e entende antes de gastar.




