
Azure Container Apps em produção: Jobs, networking, observabilidade e troubleshooting - Parte 2

Introdução
Na Parte 1, cobrimos os fundamentos de Container Apps: posicionamento no ecossistema Azure, conceitos de Environment, Revisions e Replicas, implementação prática com CLI e Bicep, escala automática com KEDA e integração com Dapr para microserviços. Agora, vamos avançar para os temas operacionais que completam uma arquitetura de produção.
Nesta segunda parte, exploraremos Jobs para batch processing, networking com VNet e Private Endpoints, observabilidade com KQL e OpenTelemetry, blue-green deployments com traffic splitting, troubleshooting dos erros mais comuns e uma arquitetura de referência completa.
Azure Container Apps Jobs
Jobs são uma adição essencial ao Container Apps para workloads que executam e terminam — diferente de apps que ficam rodando continuamente. Existem três modos de execução:
Job Manual (sob demanda)
Ideal para tarefas administrativas ou processamento one-off:
# Criar o job
az containerapp job create \
--name job-migracao-dados \
--resource-group $RESOURCE_GROUP \
--environment $ENVIRONMENT \
--image acrprod.azurecr.io/migracao:v1.0.0 \
--trigger-type Manual \
--replica-timeout 3600 \
--replica-retry-limit 3 \
--cpu 2.0 \
--memory 4.0Gi \
--secrets "db-source=..." "db-target=..." \
--env-vars "SOURCE_DB=secretref:db-source" "TARGET_DB=secretref:db-target"
# Executar o job
az containerapp job start \
--name job-migracao-dados \
--resource-group $RESOURCE_GROUP
Job Agendado (Cron)
Para tarefas recorrentes como cleanup, relatórios, ou ETL:
az containerapp job create \
--name job-relatorio-diario \
--resource-group $RESOURCE_GROUP \
--environment $ENVIRONMENT \
--image acrprod.azurecr.io/relatorio:v2.0.0 \
--trigger-type Schedule \
--cron-expression "0 6 * * *" \
--replica-timeout 1800 \
--parallelism 1 \
--replica-completion-count 1 \
--cpu 1.0 \
--memory 2.0Gi
A expressão "0 6 * * *" executa o job todos os dias às 6h UTC.
Job Event-Driven
O modo mais poderoso — jobs que escalam baseado em eventos (funciona com os mesmos scalers KEDA):
az containerapp job create \
--name job-processar-video \
--resource-group $RESOURCE_GROUP \
--environment $ENVIRONMENT \
--image acrprod.azurecr.io/video-processor:v1.0.0 \
--trigger-type Event \
--min-executions 0 \
--max-executions 10 \
--polling-interval 30 \
--scale-rule-name queue-trigger \
--scale-rule-type azure-queue \
--scale-rule-metadata \
"queueName=videos-processar" \
"queueLength=1" \
"accountName=stprodvideos" \
--scale-rule-auth \
"connection=storage-conn" \
--secrets "storage-conn=..." \
--cpu 2.0 \
--memory 4.0Gi \
--replica-timeout 7200
Cada mensagem na fila dispara uma execução independente do job. Quando a fila esvazia, nenhum job está rodando (custo zero).
Networking: VNet integration e Private Endpoints
Em produção, você raramente quer seus apps expostos diretamente à internet sem controle de rede.
Deploy em VNet
# Criar VNet e subnet dedicada para Container Apps
az network vnet create \
--name vnet-producao \
--resource-group $RESOURCE_GROUP \
--location $LOCATION \
--address-prefix 10.0.0.0/16
az network vnet subnet create \
--name snet-containerapps \
--resource-group $RESOURCE_GROUP \
--vnet-name vnet-producao \
--address-prefix 10.0.16.0/23
# Criar environment dentro da VNet
SUBNET_ID=$(az network vnet subnet show \
--name snet-containerapps \
--resource-group $RESOURCE_GROUP \
--vnet-name vnet-producao \
--query id -o tsv)
az containerapp env create \
--name env-producao-vnet \
--resource-group $RESOURCE_GROUP \
--location $LOCATION \
--infrastructure-subnet-resource-id $SUBNET_ID \
--internal-only true
O parâmetro --internal-only true faz com que nenhum app tenha IP público. Todo o tráfego fica dentro da VNet.
Expondo via Application Gateway ou Front Door
Para expor apps internos à internet de forma segura:
Opção 1 — Application Gateway (backend VNet privado):
# Obter o IP estático do environment
STATIC_IP=$(az containerapp env show \
--name env-producao-vnet \
--resource-group $RESOURCE_GROUP \
--query properties.staticIp -o tsv)
# Obter o FQDN padrão do environment
DEFAULT_DOMAIN=$(az containerapp env show \
--name env-producao-vnet \
--resource-group $RESOURCE_GROUP \
--query properties.defaultDomain -o tsv)
# Usar esse IP e FQDN como backend no Application Gateway
echo "Backend IP: $STATIC_IP"
echo "Backend FQDN: api-pedidos.${DEFAULT_DOMAIN}"
Opção 2 — Azure Front Door Premium (via Private Link):
Para Front Door, a integração recomendada com Container Apps privados é via Private Link. Configure o origin type como Container Apps/managed environment no Front Door Premium, que estabelece a conexão privada automaticamente. Essa abordagem evita expor IPs e funciona de ponta a ponta via backbone Microsoft.
Importante sobre TLS: quando o app está atrás de Front Door ou Application Gateway, o certificado TLS público normalmente termina na borda (Front Door/AppGW). O app interno pode usar HTTP ou TLS com certificado interno.
Private Endpoints para serviços backend
Configure seus apps para acessar databases, storage e outros serviços via Private Endpoints:
# A VNet do Container Apps já tem acesso à subnet dos private endpoints
# Basta criar os private endpoints dos serviços na mesma VNet ou com peering
az network private-endpoint create \
--name pe-sql-pedidos \
--resource-group $RESOURCE_GROUP \
--vnet-name vnet-producao \
--subnet snet-private-endpoints \
--private-connection-resource-id "/subscriptions/.../Microsoft.Sql/servers/sql-prod" \
--group-id sqlServer \
--connection-name sql-pedidos-conn
Observabilidade: logs, métricas e tracing
Container Apps envia logs e métricas automaticamente para o Log Analytics Workspace configurado no environment. Não precisa instalar agents nem sidecars de telemetria.
Consultando logs com KQL
// Logs do sistema (eventos de escala, deploys, erros de plataforma)
ContainerAppSystemLogs_CL
| where ContainerAppName_s == "api-pedidos"
| where Log_s contains "error" or Log_s contains "failed"
| project TimeGenerated, Log_s, RevisionName_s
| order by TimeGenerated desc
| take 50
// Logs da aplicação (stdout/stderr do container)
ContainerAppConsoleLogs_CL
| where ContainerAppName_s == "api-pedidos"
| where Log_s !contains "healthz" // Filtrar health checks
| project TimeGenerated, Log_s, RevisionName_s, ContainerName_s
| order by TimeGenerated desc
| take 100
// Monitorar escala automática
ContainerAppSystemLogs_CL
| where ContainerAppName_s == "api-pedidos"
| where Log_s contains "replica" or Log_s contains "scale"
| project TimeGenerated, Log_s
| order by TimeGenerated desc
Métricas essenciais para alertas
Configure alertas no Azure Monitor para estas métricas críticas:
| Métrica | Threshold sugerido | Ação |
|---|---|---|
Requests | Baseline + 200% | Alert de tráfego anômalo |
ResponseTime (preview) | > 2 segundos | Alert de latência |
Replicas | > 80% do max | Considerar aumentar max-replicas |
RestartCount | > 3 em 5 min | Alert de instabilidade |
UsageNanoCores | > 80% do alocado | Alert de saturação de CPU |
WorkingSetBytes | > 85% do alocado | Alert de saturação / OOM iminente |
Alertas via CLI
# Alerta de latência alta (ResponseTime > 2s — preview)
APP_ID=$(az containerapp show \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--query id -o tsv)
az monitor metrics alert create \
--name "alerta-latencia-api-pedidos" \
--resource-group $RESOURCE_GROUP \
--scopes "$APP_ID" \
--condition "avg ResponseTime > 2" \
--description "Latência média acima de 2 segundos" \
--severity 2 \
--action "/subscriptions/.../actionGroups/ag-oncall-sre"
# Alerta de réplicas no máximo
az monitor metrics alert create \
--name "alerta-replicas-max" \
--resource-group $RESOURCE_GROUP \
--scopes "$APP_ID" \
--condition "avg Replicas >= 18" \
--description "App próximo do limite de réplicas (max: 20)" \
--severity 3 \
--action "/subscriptions/.../actionGroups/ag-oncall-sre"
Distributed Tracing com OpenTelemetry
Container Apps suporta OpenTelemetry nativamente. Configure o environment para enviar traces e logs (recurso em preview):
# Configurar OpenTelemetry no environment (preview)
az containerapp env telemetry app-insights set \
--name $ENVIRONMENT \
--resource-group $RESOURCE_GROUP \
--connection-string "InstrumentationKey=xxx;IngestionEndpoint=https://brazilsouth-1.in.applicationinsights.azure.com/" \
--enable-open-telemetry-traces true \
--enable-open-telemetry-logs true
Importante: a configuração do environment habilita a coleta, mas traces de aplicação ainda exigem instrumentação OTel no seu código. Para traces do Dapr, configure também daprAIInstrumentationKey no environment.Na sua aplicação, configure o SDK do OpenTelemetry para exportar via OTLP:
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
# O Container Apps configura OTEL_EXPORTER_OTLP_ENDPOINT automaticamente
provider = TracerProvider()
processor = BatchSpanProcessor(OTLPSpanExporter())
provider.add_span_processor(processor)
trace.set_tracer_provider(provider)
tracer = trace.get_tracer(__name__)
@app.route('/pedidos', methods=['POST'])
def criar_pedido():
with tracer.start_as_current_span("criar-pedido") as span:
span.set_attribute("pedido.tipo", "express")
# ... lógica do pedido
Traffic Splitting e Blue-Green Deployments
Uma das features mais úteis em produção é a capacidade de dividir tráfego entre revisions — essencial para deploys seguros.
Pré-requisito: Container Apps opera em single revision mode por padrão. Para traffic splitting, você precisa habilitar multiple revision mode primeiro:
az containerapp revision set-mode \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--mode multiple
Nota para workers/event-driven: múltiplas revisions ativas podem consumir mensagens da mesma fila em paralelo, gerando comportamento inesperado. Prefira single revision mode para workers e use traffic splitting apenas para apps com ingress HTTP.
Canary Release
# Deploy de nova versão (cria nova revision automaticamente)
az containerapp update \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--image acrprod.azurecr.io/api-pedidos:v1.3.0 \
--revision-suffix v1-3-0
# Enviar 10% do tráfego para a nova versão
az containerapp ingress traffic set \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--revision-weight \
api-pedidos--v1-2-0=90 \
api-pedidos--v1-3-0=10
# Se tudo OK, promover para 100%
az containerapp ingress traffic set \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--revision-weight \
api-pedidos--v1-3-0=100
# Desativar a revision antiga
az containerapp revision deactivate \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--revision api-pedidos--v1-2-0
Labels para testes direcionados
Você pode atribuir labels a revisions para acessá-las diretamente (sem afetar tráfego de produção):
# Label para teste da nova versão
az containerapp revision label add \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--revision api-pedidos--v1-3-0 \
--label staging
# Acessar diretamente: https://api-pedidos---staging.<domain>
Troubleshooting: erros comuns e soluções
1. Container falha ao iniciar (CrashLoopBackOff equivalente)
Sintoma: Revision está com status "Failed" ou "Degraded".
# Verificar logs do sistema
az containerapp logs show \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--type system \
--follow
# Verificar logs do container
az containerapp logs show \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--type console \
--follow
Causas comuns:
- Porta do
--target-portnão coincide com a porta que o app escuta - Imagem não encontrada no registry (credenciais inválidas)
- Container excede os limites de CPU/memória ao iniciar
- Health check (liveness probe) falhando antes do app estar pronto
2. Escala não funciona como esperado
Sintoma: App não escala acima de 1 réplica ou não escala para zero.
// Verificar eventos de escala
ContainerAppSystemLogs_CL
| where ContainerAppName_s == "api-pedidos"
| where Log_s contains "Scal"
| project TimeGenerated, Log_s
| order by TimeGenerated desc
| take 20
Causas comuns:
min-replicasdefinido como 1 (não permite escala a zero)- Secret da fila/service bus expirado ou inválido
- Nome da fila com typo no scale rule
concurrentRequestsmuito alto (1000) — raramente atinge o threshold
3. Timeout em chamadas entre serviços
Sintoma: Chamadas via Dapr retornam timeout ou 500.
Soluções:
- Verificar se o
--dapr-app-idestá correto em ambos os serviços - Confirmar que ambos os apps estão no mesmo environment
- Verificar se o
--dapr-app-portcorresponde à porta real do app - Aumentar o timeout do Dapr se o processamento for pesado
4. OOMKilled (Out of Memory)
Sintoma: Container reinicia repetidamente, logs mostram "OOMKilled".
# Aumentar memória
az containerapp update \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--cpu 1.0 \
--memory 4.0Gi
Combinações válidas de CPU/Memory:
| CPU (cores) | Memória (GiB) |
|---|---|
| 0.25 | 0.5 |
| 0.5 | 1.0 |
| 0.75 | 1.5 |
| 1.0 | 2.0 |
| 1.25 | 2.5 |
| 1.5 | 3.0 |
| 1.75 | 3.5 |
| 2.0 | 4.0 |
| 2.25 | 4.5 |
| 2.5 | 5.0 |
| 2.75 | 5.5 |
| 3.0 | 6.0 |
| 3.25 | 6.5 |
| 3.5 | 7.0 |
| 3.75 | 7.5 |
| 4.0 | 8.0 |
Nota: A razão é sempre 2:1 (memória = 2× CPU em GiB), com incrementos de 0.25 vCPU. Em ambientes Consumption only (sem workload profiles), o limite máximo pode ser menor. Ambientes com workload profiles suportam até 4 vCPU / 8 GiB no perfil Consumption e ainda mais em perfis dedicados.
5. Custom domain com TLS não funciona
# Adicionar custom domain com certificado managed
az containerapp hostname add \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--hostname api.meudominio.com.br
# Vincular certificado managed gratuito (emitido pelo Azure)
az containerapp hostname bind \
--name api-pedidos \
--resource-group $RESOURCE_GROUP \
--hostname api.meudominio.com.br \
--environment $ENVIRONMENT \
--validation-method CNAME
Requisitos: O CNAME do DNS deve apontar para o FQDN do app antes de vincular o certificado. O app precisa ter ingress público para validação — para apps atrás de Front Door/Application Gateway, o TLS público termina na borda.
Arquitetura de referência: e-commerce com microserviços
Para consolidar tudo, aqui está uma arquitetura de referência realista:
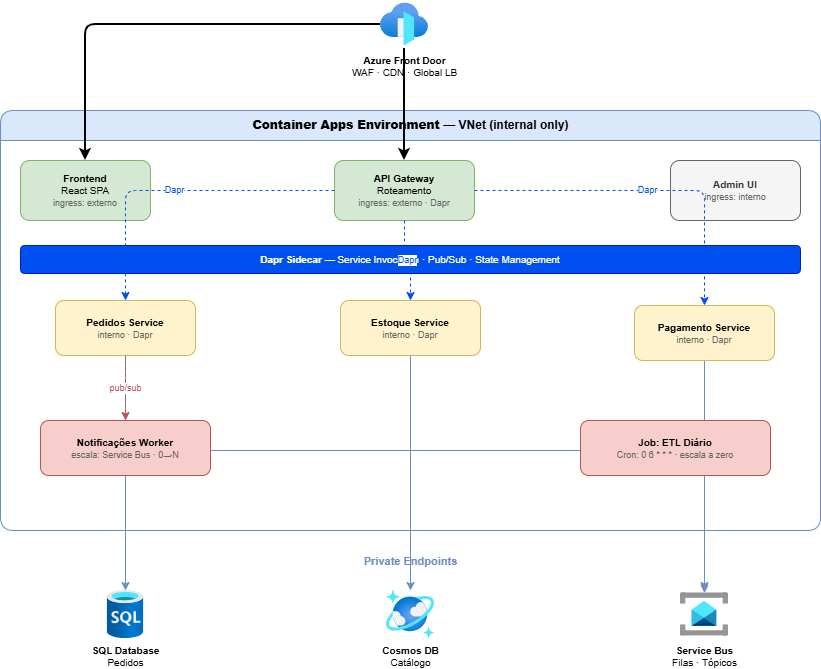
Componentes e decisões:
- Frontend: App estático React servido pelo Container Apps (ingress externo). Escala por HTTP.
- API Gateway: Container App com ingress externo, roteia para serviços internos via Dapr.
- Serviços de domínio: Pedidos, Estoque, Pagamento — todos com Dapr habilitado, ingress interno, comunicação via service invocation.
- Notificações Worker: Escala baseada em mensagens no Service Bus (pub/sub via Dapr). Escala a zero quando não há mensagens.
- Job ETL: ACA Job agendado (Cron) para consolidar dados de vendas diariamente.
- Backends: SQL Database, Cosmos DB e Service Bus acessados via Private Endpoints na mesma VNet.
Conclusão e próximos passos
O Azure Container Apps preenche uma lacuna importante no ecossistema Azure: a capacidade de rodar containers em produção com escala automática inteligente, integração nativa com Dapr para microserviços, e Jobs para batch processing — tudo sem a complexidade operacional do Kubernetes.
Os pontos-chave deste artigo:
- Escolha de plataforma: Container Apps é ideal para microserviços, APIs e workers event-driven. Se você precisa de controle total sobre o cluster, AKS continua sendo a escolha certa.
- Escala é o diferencial: A integração transparente com KEDA permite escala baseada em dezenas de fontes de eventos, com escala a zero real.
- Dapr simplifica microserviços: Service invocation, pub/sub e state management sem código de infraestrutura.
- Jobs completam o ecossistema: Workloads batch, ETL e processamento sob demanda com as mesmas facilidades de escala.
- Networking para produção: VNet integration com internal-only environments e Private Endpoints para backends.
- Observabilidade nativa: Logs, métricas e tracing com zero configuração adicional.
No próximo artigo, exploraremos Platform Engineering no Azure, mostrando como construir Internal Developer Platforms com Azure Deployment Environments e Dev Box para acelerar o ciclo de desenvolvimento das equipes.
Referências
- Documentação oficial: Azure Container Apps
- Container Apps vs AKS — guia de decisão
- Escala automática com KEDA no Container Apps
- Dapr no Azure Container Apps
- Azure Container Apps Jobs
- Networking no Container Apps
- Observabilidade e logging
- What's new in Azure Container Apps at Ignite'25
- Dapr Docs — Azure Container Apps




