
Kubernetes - Como processar 1 Milhão de requests (1600 RPS) a cada 10 minutos?
O desafio do cliente era atingir 800 RPS. Com o Kubernetes não só atingimos a meta, como dobramos para 1600 RPS.

O objetivo inicial do projeto era claro: atingir 800 requisições por segundo (RPS) na aplicação.
O ambiente existente contava com quatro VMs Linux executando uma aplicação Python com Gunicorn, onde o cliente ajustava o número de workers manualmente para escalar horizontalmente.
Em uma VM de 32 vCPUs, o desempenho era limitado. Em outra com 64 vCPUs, os resultados melhoravam. O suficiente para o cliente concluir que a solução ideal seria simplesmente "aumentar o tamanho da máquina".
Foi nesse ponto que fomos acionados para ajudar nos testes.
1. Diagnóstico do Cenário
Logo na primeira reunião ficou evidente que o problema não era apenas de CPU.
O verdadeiro gargalo estava na estratégia de escala e no formato do ambiente:
- Quatro VMs atrás de um Load Balancer
- Cada nova réplica exigia provisionar e configurar manualmente uma nova VM
- Processo de deployment complexo
- Setup de teste lento e difícil de reproduzir
- Monitoramento fragmentado
- Alto risco de erro humano
- Baixa capacidade de experimentar novas variações de configuração
Tecnicamente o ambiente funcionava, mas não era reprodutível, automatizado ou elástico.
A recomendação foi direta: migrar para Kubernetes.
2. Motivação Técnica para usar Kubernetes
A decisão não foi tomada por modismo. Ela se baseou em critérios técnicos claros:
-
A aplicação era adequada para containers - O código estava bem estruturado, padronizado e já utilizava containers, o que reduz drasticamente o custo de entrada no Kubernetes.
-
Necessidade real de escala horizontal: Subir VMs manualmente e configurar não atendia à dinâmica dos testes. Era muito trabalhoso e suscetível a falha humana.
-
Imutabilidade e previsibilidade: Containers garantem ambientes idênticos em cada réplica, reduzindo inconsistências e simplificando testes.
Mas nem tudo são flores, ao pensar em usar Kubernetes, precisamos responder a pergunta:
“A complexidade do Kubernetes compensa a eliminação dessas dores que estamos tendo?”
Neste caso, a resposta foi um sonoro: Sim, compensava. E muito.
3. Construção do Ambiente
Na arquitetura do novo ambiente priorizamos automação, governança e replicabilidade.
3.1. Provisionamento com Terraform
Todo o cluster AKS e seus componentes foram provisionados via IaC, permitindo:
- destruição e recriação rápidas
- versionamento
- consistência entre ambientes
- segurança operacional
Após subir o ambiente, implantamos ArgoCD para GitOps e a partir dele configuramos
- ArgoCD - Sim, o ArgoCD gerenciando o próprio ArgoCD, além de gerenciar o ciclo de vida de todas aplicações e componentes do Cluster
- Ingress NGINX – Configurado para exportar métricas para o prometheus.
- Kube Prometheus Stack – monitoramento completo do cluster e pods
- Cert-Manager – automação de certificados TLS
A partir desse ponto, nenhuma configuração era manual.
Toda alteração passava por Git, garantindo auditoria e previsibilidade.
4. Obstáculos durante os testes
Dois problemas surgiram logo no início:
4.1. Conflito de CIDR no peering da VNet
O CIDR do cliente conflitou com a rede que subimos para o AKS. Solução?
Recriamos todo o cluster com um novo CIDR em menos de 30 minutos, graças ao Terraform.
4.2. Subnet insuficiente
A subnet original tinha apenas um /22, cerca de 1024 IPs.
Durante os testes percebemos rapidamente que isso se tornou um problema. Advinha qual foi a solução?
Recriamos o cluster com uma subnet /17 em menos de 30 minutos, oferecendo mais de 32 mil IPs. E reconfiguramos as aplicações em minutos.
Sem IaC + GitOps, esses ajustes levariam dias.
Com a automação, levaram minutos.
5. Testes de Carga
Com o ambiente pronto, o foco passou para o comportamento da aplicação.
O cliente finalmente pôde testar cenários que antes eram inviáveis:
- VMs menores com mais pods
- VMs maiores com menos pods
- Ajustes de memória e CPU no Deployment
- Troca de família de máquinas
- Uso intensivo do HPA
- Testes A/B de configurações de Gunicorn
E tudo isso era modificado por simples operações:
git commit
git push
ou
terraform apply
Qualquer cenário proposto passou a ser parte natural dos testes. Sem rebuild manual. Sem horas de setup. Sem retrabalho.
6. Resultado Final
A meta era 800 RPS.
Após otimizações no cluster e ajustes finos na aplicação, atingimos 1600 RPS, até saturar o banco, o que era esperado dentro dos limites atuais.
O mais importate era que com 800 RPS, o banco se manteve estável, garantindo o objetivo do negócio.
Resumo dos números:
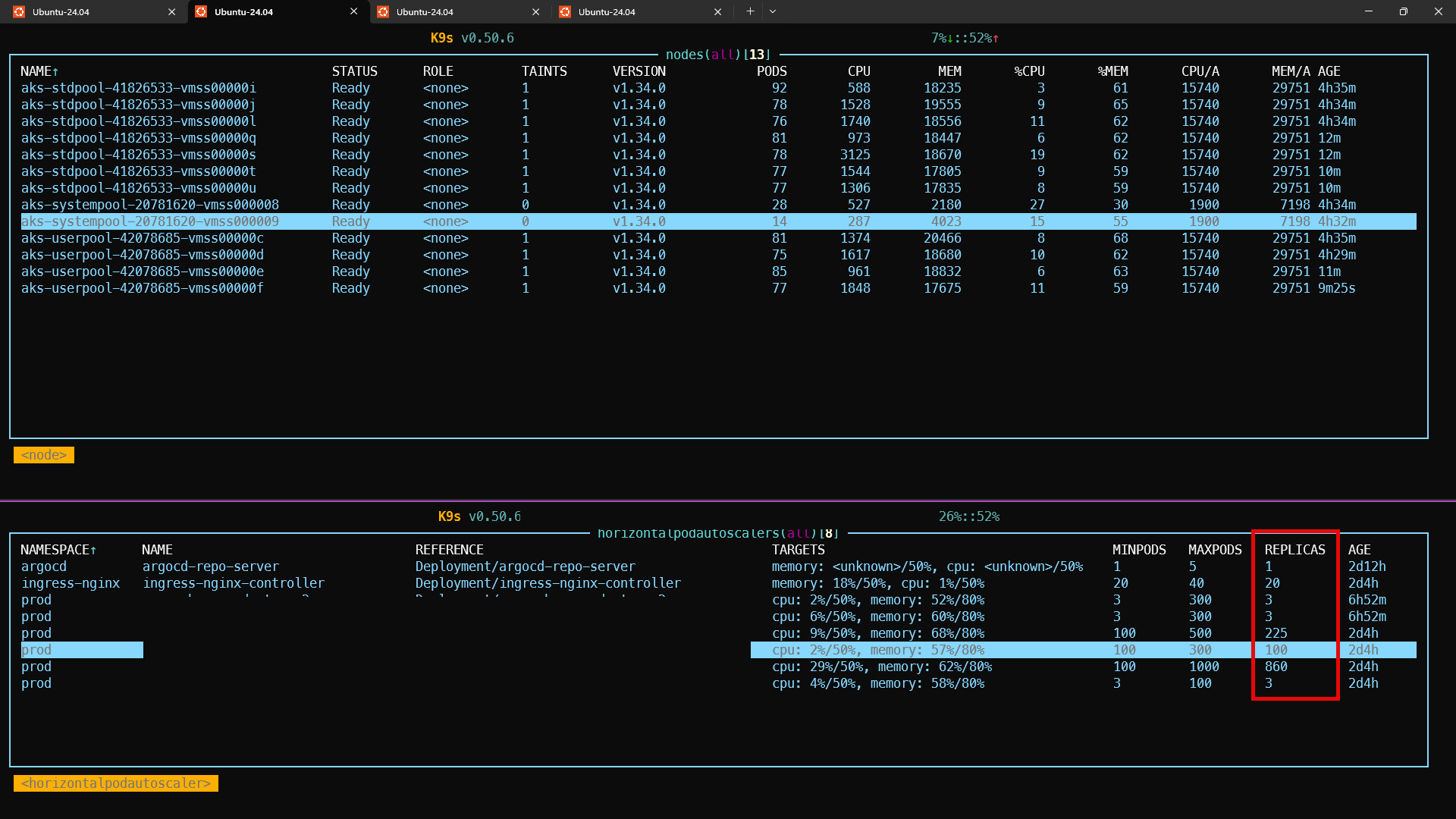
- 4 réplicas fixas (modelo antigo)
- +1000 pods (modelo novo)
- Uma aplicação atingiu 860 réplicas via HPA
- Escalabilidade linear
- Ambiente 100% reprodutível
- Toda infraestrutura versionada e recriável via Terraform
- Todas as aplicações gerenciadas por GitOps com ArgoCD
- Testes de carga totalmente replicáveis
- Redução clara de custos operacionais
- Escala horizontal real, atingindo centenas de pods em minutos
E o cliente ainda teve a cereja no bolo:
❯ O custo final do ambiente ficou menor do que o ambiente baseado em VMs grandes.
7. Considerações finais
Se antes uma nova réplica era um desafio, agora é um número num arquivo yaml.
Introduzir Kubernetes não elimina complexidade, ele a organiza.
É uma plataforma poderosa, mas é complexa.
No entanto, quando bem utilizado:
- melhora a previsibilidade
- reduz custos
- aumenta a resiliência
- permite experimentação rápida
- aumenta drasticamente a capacidade de escala
No caso deste cliente, Kubernetes foi a peça que possibilitou alcançar, e dobrar, a meta de throughput.
Simples? Não.
Simplório? Jamais.
Eficaz? Com absoluta certeza.




